[Note] EvoRoute: Experience-Driven Self-Routing LLM Agent Systems
Agent System Trilemma
- performance ($i.e.$, task success and accuracy)
- efficiency ($i.e.$, time or steps required to complete tasks)
- cost ($i.e.$., computational and monetary resources consumed)
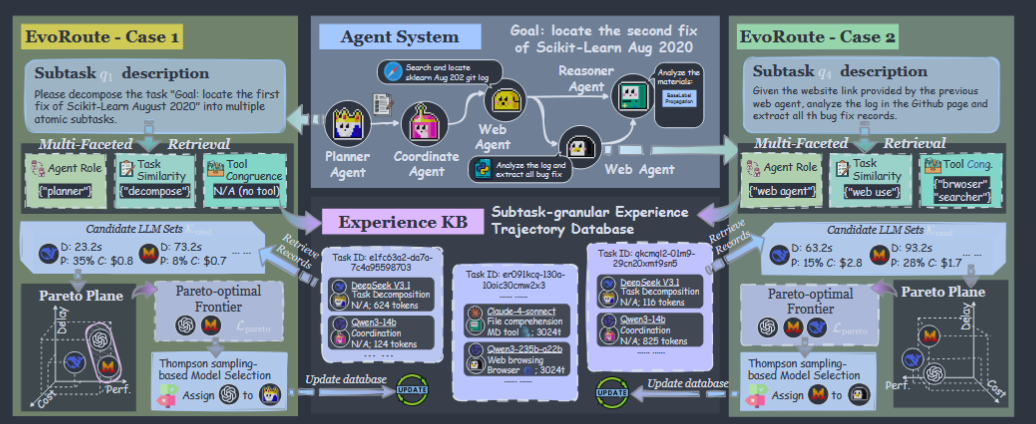
EvoRoute
A self-evolving routing paradigm that dismantles the trilemma through fine-grained model selection. Before executing each step, it dynamically selects the most judicious LLM by:
- retrieval: performing a multifaceted retrieval to identify historically analogous sub-task executions from an evolving knowledge base;
- filtration: distilling a Pareto-optimal set of candidate models, $i.e.$, those that are not dominated across the axes of cost, efficiency, and performance;
- selection: leveraging a lightweight decision model to make the final selection based on this rich, context-aware statistical evidence.
Notations
\[\mathcal{M} = \langle \mathcal{I}, \mathcal{L}, \phi, \mathcal{S}, \mathcal{T}, \mathcal{A}, \Psi, \mu, \mathcal{Q} \rangle,\]- $\mathcal{M}$: the designed complex agentic AI system
- \(\mathcal{I} = \{1,2,...,N\}\): the set of agent roles ($e.g.$, web-browser, coder)
- $\mathcal{L}$: the pool of available LLM backbones
- $\phi:\mathcal{I}\rightarrow\mathcal{L}$
- $\mathcal{S}$ : system state, typically implemented as a shared memory or scratchpad
- $\mathcal{T}$: a set of external tools, such as code interpreters or web search APIs
- $\mathcal{A}$: the full action space, including both natural language actions and tool invocations, formally $\mathcal{A}=\mathcal{A}_{lang}\cup{\text{use_tool}(T,args)\mid T\in\mathcal{T}}$
- \(\Psi\{s_{t+1}\mid s_t,a_t\}\) governs the transition dynamics of the system
- $\mu(t)\in\mathcal{I}$ selects the active agent at each time step $t$
Objective Formulation
\[\rho^* = \arg\max_\rho \left( \mathbb{E}_{\tau \sim \rho}[\mathbb{P}(\tau)], -\mathbb{E}_{\tau \sim \rho}[\mathbb{C}(\tau)], -\mathbb{E}_{\tau \sim \rho}[\mathbb{D}(\tau)] \right)\]- $\rho$: the dynamic routing policy that selects an LLM $l_t\in\mathcal{L}$ for the active agent at each step $t$
- $\mathbb{P}(\tau)$: task performance
- $\mathbb{C}(\tau)$: the cumulative monetary and computational expenditure
- $\mathbb{D}(\tau)$: the total wall-clock execution time
- $\tau=(s_0,a_0,s_1,a_1,…,s_T)$: the full execution trajectory of the system
Methodology
Step-level experience base
The backbone of EvoRoute is an evolving knowledge base $\mathcal{K}$ built from prior executions. After a task finishes, the full trajectory is split into step-level records:
\[\mathcal{R_t} = \langle i_t, l_t, q_t, e_t, T_t, c_t, d_t, \sigma_t, \mathbb{P}(\tau) \rangle,\]Each record stores:
- $i_t$: active agent role,
- $l_t$: LLM used at this step,
- $q_t$: sub-task instruction,
- $e_t$: embedding of the instruction,
- $T_t$: tools used,
- $c_t$: cost,
- $d_t$: wall-clock duration,
- $\sigma_t$: whether the step executed successfully,
- $\mathbb{P}(\tau)$: final task-level success signal.
After each run:
\[\mathcal{K}\leftarrow\mathcal{K}\cup\{\mathcal{R}_t\}^{T-1}_{t=0}\]Multi-Faceted Retrieval
When a new step arrives, EvoRoute retrieves relevant historical records from $\mathcal{K}$. Instead of relying on one notion of similarity, it uses three.
Agent Role Match
\[\mathcal{K}_{\text{agent}}=\{\mathcal{R}_t\in\mathcal{K}\mid i_t=i_{t'}\}\]Semantic Similarity Retrieval
\[\mathcal{K}_{\text{sem}} = \{\mathcal{R}_t \in \mathcal{K} \mid \text{sim}(\text{Embed}(q_{t'}), e_t) \geq \theta_{\text{sim}}\}\]- $\text{Embed}(\cdot)$ is implemented via MiniLM
- $\theta_{\text{sim}}=0.85$
Tool Congruence Retrieval
\[\mathcal{K}_{\text{tool}} = \{\mathcal{R}_t \in \mathcal{K} \mid T_t \cap \text{PredictTools}(q_{t'}) \neq \emptyset\}.\]$\text{PredictTools}(\cdot)$ uses a two-stage predictor:
- Keyword heuristic
- Using a predefined dictionary to map explicit trigger keywords(e.g., “search” for $\text{web_search}$; “run”, “plot” for $\text{code_interpreter}$)
- Cheap LLM fallback
- if heuristics fail, use Qwen3-14B in zero-shot mode
- Keyword heuristic
The final candidate set:
\[\mathcal{K}_{\text{cand}}=\mathcal{K}_{\text{agent}}\cup\mathcal{K}_{\text{sem}}\cup\mathcal{K}_{\text{tool}}\]Pareto-Optimal Filtration and Selection
From the retrieved records, EvoRoute extracts candidate models:
\[\mathcal{L}_{\text{cand}}=\{l_t\mid\mathcal{R}_t\in\mathcal{K}_{\text{cand}}\}\]For each candidate model $l\in\mathcal{L}_{\text{land}}$, it estimates:
- average performance $\hat{P}(l)$
- average cost $\hat{C}(l)$
- average delay $\hat{D}(l)$
A model is dominated if another model exists that is superior or equal on all three axes and strictly superior on at least one.
Retaining only the non-dominated models, we form the Pareto-optimal set, $\mathcal{L}_{\text{pareto}}$
Thompson-sampling-based model selection
If EvoRoute always picked the current best average, it would become too greedy and stop learning.
It assumes each metric follows a Normal distribution and models the uncertainty over its mean and variance using a Normal-Inverse-Gamma conjugate prior.
First, compute the sample statistics for each metric \(m \in \{\mathbb{P},\mathbb{C},\mathbb{D}\}\): the count $n_l$, the sample mean \(\overline{x}_{m,l}\) and the sample variance \(s^2_{m,l}\). These statistics are used to parameterize the NIG posteriors, NIG(\(\mu_{m,l},v_{m,l},\alpha_{m,l},\beta_{m,l}\)), where \(\mu_{m,l}=\overline{x}_{m,l}\), $v_{m,l}=n_l$, \(\alpha_{m,l}=n_l/2\), and \(\beta_{m,l}=(n_l-1)s^2_{m,l}/2\)
At decision time, it samples a stochastic utility:
\[U'(l) = w_p \cdot \tilde{x}_{P,l} - w_c \cdot \tilde{x}_{C,l} - w_d \cdot \tilde{x}_{D,l}\]and selects: \(l^* = \arg\max_{l \in \mathcal{L}_{\text{pareto}}} (U'(l)),\)
where $(w_p,w_c,w_d)$ reflect the desired trilemma trade-off ($w_p=1.0$, $w_c=0.1$, $w_d=0.05$)
Crucially, this selection is not the end of the process. Once the agent powered by $l^∗$ completes its action, the observed outcome is logged back into the knowledge base $\mathcal{K}$. This closes the feedback loop, ensuring that every decision and its outcome contribute to the system’s ever-improving wisdom, thereby realizing the self-evolving nature of EvoRoute.