[Note] FreeKV: Boosting KV Cache Retrieval For Efficient LLM Inference
Summary
FreeKV, a training-free algorithm-system co-optimization framework that boosts the efficiency of KV retrieval, while maintaining near-lossless model accuracy across diverse scenarios.
Why KV retrieval
For complex tasks involving long generation, the accuracy of KV dropping will drop a lot. See as the Figure bellow.
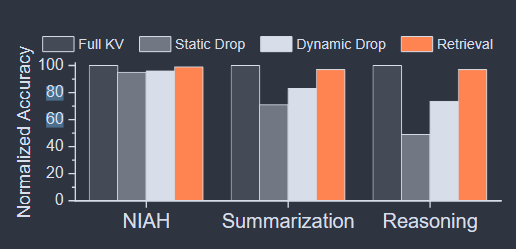
KV retrieval challenge
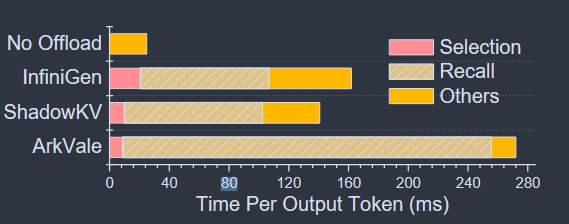
This method require the complete KV cache retained, so retrieval methods often offload the KV cache to CPU memory to circumvent GPU memory limitations.
- No Offload (Quest) → out-of-memory errors are inevitable for long contexts;
- Offload (ArkVale, ShadowKV, InfiniGen)→ high latency
- Low bandwidth of CPU-GPU connection → $recalling$ the selected KV tuples from CPU to GPU incurs long latency;
- Select KV tuples from entire context → considerable $selection$ overhead.

FreeKV Algorithm design
Speculative Retrieval → The similarity between the query vectors of adjacent generated tokens is quite high (mean 0.84).
Fine-Grained Correction → While the mean similarity remains high, certain decoding steps exhibit outliers with significantly lower similarity.
Hybrid Layouts and Streamed Recall → Effective recall overlapping to minimize overhead demands high recall efficiency.
Speculative Retrieval
The attention computation of step $i$ is launched by reusing the KV tuples recalled during step $i-1$.
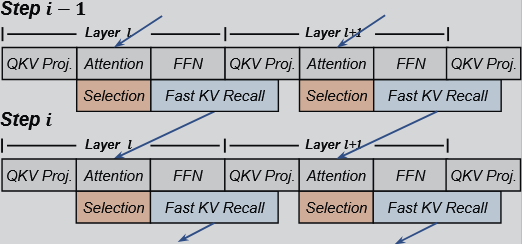
FreeKV adopts page-wise selection, utilizing the min-max pooled keys within each page as the page summary, similar to Quest.
Fine-Grained Correction
- Correction is triggered only if $C_i\lt \tau$, where $C_i$ is the cosine similarity of query vectors and $\tau$ is predefined threshold.
- Once the KV heads requiring correction, FreeKV initiates selection and recall for these KV heads before the attention computation. For KV heads that do not need correction, recall is deferred and overlapped with other operation.
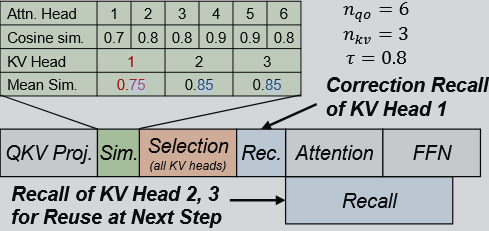
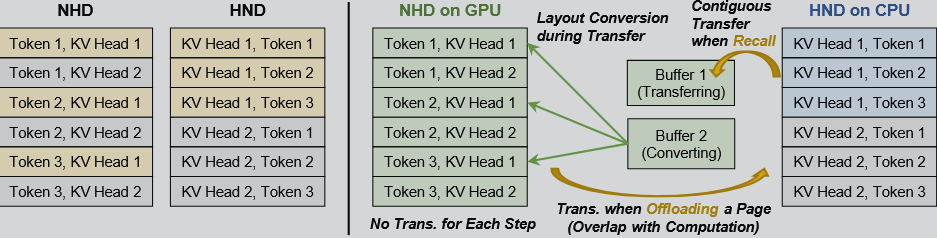
Hybrid Layouts and Streamed Recall
I’m not familiar with KV cache layout, maybe I’ll write another blog about these things (NHD and HND) a few days later.
System overview of FreeKV:
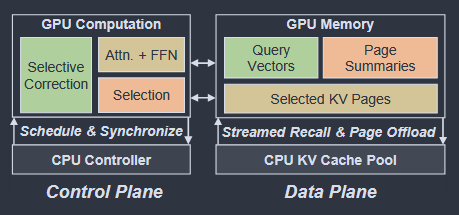
- GPU (NHD) → query vectors from the previous step, page summaries and cache for selected KV pages.
- CPU (HND) → complete KV cache pool for offloading KV pages.
- $double-buffering$: After a selected KV page is transferred to buffer 2, its layout conversion begins immediately, while the transfer of the next page is concurrently initiated into buffer 1